
In this blog post, our Principal Consultant Rohit Misuriya dives into the OWASP Top 10 for Agentic Applications (2026), a groundbreaking framework that addresses the unique security risks posed by autonomous AI agents. The blog covers everything from the fundamentals of agentic AI and what makes it different from traditional LLM applications to detailed breakdowns of each of the ten risks, real-world incidents, exploitation scenarios, and actionable mitigation strategies.
Rohit unpacks the critical nuances of securing agentic systems, including the challenges of agent goal hijacking, tool misuse, identity abuse, supply chain compromise, and the cascading failure modes that emerge when autonomous agents interact with each other and the real world.
TL;DR
- Agentic AI systems go beyond traditional chatbots. They autonomously plan, reason, use tools, and take real-world actions with minimal human oversight, introducing an entirely new class of security risks.
- The OWASP Top 10 for Agentic Applications (2026), released in December 2025, is the first peer-reviewed framework specifically targeting autonomous AI security, developed with input from over 100 security experts and endorsed by organizations including NIST, Microsoft, and NVIDIA.
- The framework identifies ten critical risks (ASI01 through ASI10) covering agent goal hijacking, tool misuse, identity and privilege abuse, supply chain vulnerabilities, unexpected code execution, memory poisoning, insecure inter-agent communication, cascading failures, human-agent trust exploitation, and rogue agents.
- To mitigate these risks, organizations should treat agents as first-class identities with scoped privileges, sandbox all code execution, authenticate inter-agent communication, implement circuit breakers in multi-agent workflows, and maintain human oversight for high-impact decisions.
What is Agentic AI and Why Does It Need Its Own Framework?
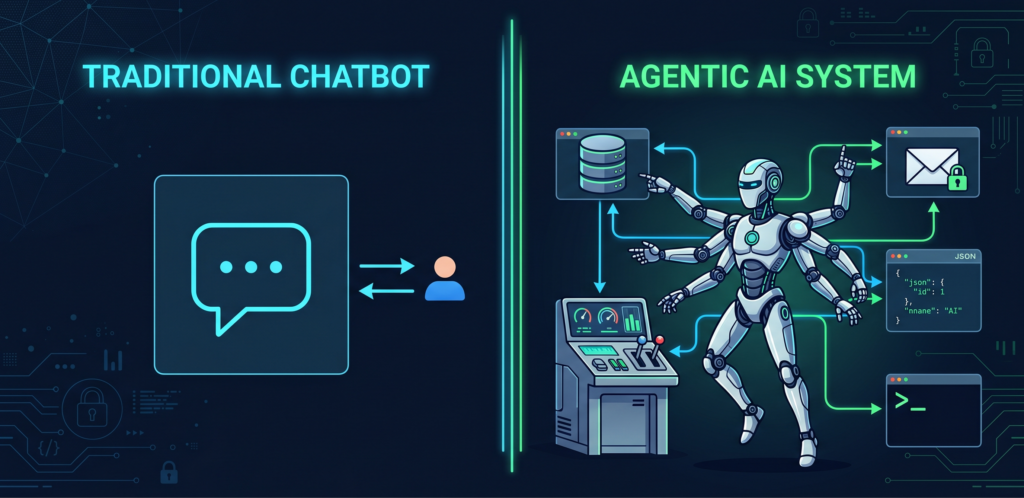
Before we dive into the Top 10, it is important to understand what distinguishes agentic AI from the LLM-based chatbots and copilots that most organizations are already familiar with. A traditional LLM application, such as ChatGPT or a customer support chatbot, operates in a request-response pattern. The user provides a prompt, the model generates a response, and the interaction is complete. The model does not take any actions beyond generating text.
Agentic AI systems are fundamentally different. They autonomously pursue complex goals by decomposing objectives into subtasks, invoking external tools such as APIs, databases, and code execution environments, and adapting dynamically based on intermediate results. They maintain persistent memory across sessions, communicate with other agents, and make decisions that have real-world consequences, including sending emails, modifying files, executing code, and triggering downstream workflows, often without human intervention at each step.
This autonomy is precisely what makes them powerful. It is also what makes them dangerous. The attack surface of an agentic system is not limited to traditional software vulnerabilities. It extends to any text the agent reads, any tool it invokes, any memory it retains, and any agent it communicates with.
The existing OWASP Top 10 for LLM Applications, while valuable, was not designed to address these emergent risks. The LLM Top 10 focuses primarily on model-level vulnerabilities such as prompt injection, training data poisoning, and output handling. Agentic systems inherit all of those risks and introduce entirely new vulnerability classes arising from autonomy, tool integration, multi-agent coordination, and persistent state. Recognizing this gap, the OWASP GenAI Security Project launched the Agentic Security Initiative and, in December 2025, released the OWASP Top 10 for Agentic Applications (2026), a peer-reviewed framework developed with input from over 100 security researchers, industry practitioners, and leading cybersecurity providers. The framework was further evaluated by a Distinguished Expert Review Board that includes representatives from NIST, the Alan Turing Institute, Microsoft’s AI Red Team, AWS, and others.
Now that we have established the context, let us examine each of the ten risks, the real-world incidents that illustrate them, and the mitigations that organizations should implement.
ASI01: Agent Goal Hijack

Description
Agent Goal Hijack occurs when an attacker manipulates an agent’s objectives, task selection, or decision pathways through techniques including, but not limited to, prompt-based manipulation, deceptive tool outputs, malicious artefacts, forged agent-to-agent messages, or poisoned external data. Unlike traditional software exploitation, where an attacker needs to modify code, AI agents can be redirected through natural language alone. If an agent processes external content such as emails, documents, web pages, or calendar invites, that content can contain hidden instructions that hijack the agent’s goals.
This fundamentally breaks the traditional security model because the attack surface is no longer just code. It is any text the agent reads.
How It Works
AI agents exhibit autonomous ability to execute a series of tasks to achieve a goal. However, due to inherent weaknesses in how natural-language instructions and related content are processed, agents and the underlying model cannot reliably distinguish instructions from related content. An attacker can exploit this by embedding hidden instructions in data that the agent processes as part of its normal workflow.
The attack vectors for goal hijacking include direct goal manipulation through explicit prompt injection, indirect instruction injection through hidden instructions in documents, RAG content, or tool outputs, and recursive hijacking where goal modifications propagate through agent reasoning chains or self-modify over time.
Real-World Incidents
EchoLeak (CVE-2025-32711): This was the first real-world zero-click prompt injection exploit in a production agentic AI system. Researchers at Aim Security discovered that Microsoft 365 Copilot could be tricked into exfiltrating data via a single crafted email. The attacker would send an email containing hidden prompts to the victim. When Copilot processed the email as part of its normal summarization workflow, the hidden instructions would redirect the agent to extract sensitive data from the victim’s mailbox and encode it into a URL that was then silently accessed. No user interaction was required.
GitHub Copilot YOLO Mode (CVE-2025-53773): Malicious instructions hidden in repositories, specifically in README files, code comments, and GitHub issues, could trick Copilot into modifying .vscode/settings.json to enable “YOLO mode” (auto-approve all tool calls), then execute arbitrary shell commands. The attack was wormable, and infected projects could spread to others via AI-assisted commits.
AGENTS.MD Hijacking in VS Code (CVE-2025-64660, CVE-2025-61590): VS Code Chat automatically includes AGENTS.MD in every request, treating it as an instruction set. Researchers demonstrated how a malicious AGENTS.MD could convince the agent to email internal data out of the organization during an everyday coding session.
Mitigation Strategies
To defend against agent goal hijacking, organizations should treat all external content as potentially hostile. This means implementing strict boundaries between instructions, which come from the system, and data, which comes from users or external sources. All inputs that the agent processes should be validated and sanitized before they are allowed to influence the agent’s decision-making process. Additionally, organizations should monitor for behavioral anomalies that could indicate a hijacked agent, such as unexpected tool invocations, unusual data access patterns, or actions that deviate from the agent’s intended purpose. Implementing output guardrails that verify agent actions against expected behavior patterns before execution can also significantly reduce the blast radius of a successful hijack.
ASI02: Tool Misuse and Exploitation
Description
AI agents are given tools, specifically the ability to send emails, query databases, execute commands, call APIs. These tools are features, not bugs. But an attacker who can influence the agent’s reasoning can turn those features into weapons. A coding assistant with filesystem access becomes a data exfiltration tool. A customer service bot with email capabilities becomes a phishing engine. The more powerful the agent, the more dangerous it becomes when compromised.
This entry covers cases where the agent operates within its authorized privileges but applies a legitimate tool in an unsafe or unintended way, for example, deleting valuable data, over-invoking costly APIs, or exfiltrating information.
How It Works
Tool misuse can occur through several vectors. An agent may be manipulated via prompt injection to use a tool in ways that were not intended by its designers. Alternatively, misalignment between the agent’s interpretation of a task and the developer’s intent can lead the agent to independently decide on a destructive course of action. Unsafe delegation, where an agent passes control of a powerful tool to another component without adequate safeguards, is another common vector. The key distinction between ASI02 and other risks is that the agent has legitimate access to the tool. The vulnerability lies in how the tool is used, not in unauthorized access.
Real-World Incidents
Amazon Q Code Assistant (CVE-2025-8217, July 2025): Attackers compromised a GitHub token and merged malicious code into Amazon Q’s VS Code extension (version 1.84.0). The injected code contained destructive prompt instructions designed to clean a system to a near-factory state and delete file-system and cloud resources. Combined with –trust-all-tools –no-interactive, the agent executed commands without confirmation. Nearly one million developers had the extension installed. Amazon patched to version 1.85.0 shortly after.
Langflow AI RCE (CVE-2025-34291): CrowdStrike observed multiple threat actors exploiting an unauthenticated code injection vulnerability in Langflow AI, a widely used tool for building AI agents. Attackers gained credentials and deployed malware through this widely-deployed agent framework.
OpenAI Operator Data Exposure: Security researcher Johann Rehberger demonstrated how malicious webpage content could trick OpenAI’s Operator agent into accessing authenticated internal pages and exposing users’ private data, including email addresses, home addresses, and phone numbers from sites like GitHub and Booking.com.
Mitigation Strategies
Organizations should apply the principle of least privilege to every tool an agent can access. Destructive operations, such as deleting data, modifying configurations, or sending external communications, should require explicit human approval. All tool arguments should be validated against expected schemas before execution. Organizations should also monitor for unusual tool invocation patterns, such as an agent suddenly making thousands of API calls or accessing tools that it does not normally use. Implementing rate limiting and cost caps on tool invocations can also help contain the impact of tool misuse.
ASI03: Identity and Privilege Abuse
Description
Agents often operate with significant privileges, including access to databases, cloud resources, internal APIs, and organizational data. When an agent is compromised, the attacker inherits all of those permissions. This creates a privilege inheritance problem: a coding assistant with repository access can exfiltrate source code, a scheduling agent with calendar access can map organizational structure, and a DevOps agent with deployment credentials can push malicious code to production. The agent’s access scope becomes the attacker’s access scope.
How It Works
Identity and privilege abuse in agentic systems occurs through several mechanisms. Agents may inherit overly broad permissions from the users or service accounts they run as. Cached tokens and stored credentials can be exploited long after they should have expired. Delegated permissions, where one agent grants access to another, can create transitive trust chains that are difficult to audit. And agent-to-agent trust boundaries, when they exist at all, are often implicit rather than explicitly verified.
The rapid adoption of standards like the Model Context Protocol (MCP) has made it easier than ever to connect agents to new data sources and tools. However, this also brings all the credential management challenges of traditional systems, amplified by the speed of agentic deployment. Connecting to a third-party agent or loading a dynamic tool definition introduces supply chain risk where the identity of the tool provider must be verified before the agent hands over sensitive data.
Real-World Incidents
Copilot Studio Connected Agents (December 2025): Microsoft’s “Connected Agents” feature, unveiled at Build 2025, is enabled by default on all new agents. It exposes an agent’s knowledge, tools, and topics to all other agents within the same environment with no visibility showing which agents have connected to yours. Zenity Labs exposed how attackers could impersonate organizations and execute unauthorized actions without detection.
CoPhish Attack (October 2025): Datadog Security Labs discovered a phishing technique abusing Copilot Studio agents. Attackers created malicious agents with OAuth login flows hosted on trusted Microsoft domains. When victims clicked “Login,” they were redirected to a malicious OAuth consent page. After consent, the agent captured the User.AccessToken and exfiltrated it to the attacker’s server, granting access to emails, chats, calendars, and OneNote data.
Copilot Studio Public-by-Default Agents: Microsoft Copilot Studio agents were configured to be public by default without authentication. Attackers enumerated exposed agents and pulled confidential business data directly from production environments.
Mitigation Strategies
Organizations should treat agents as first-class identities with explicit, scoped permissions. This means implementing the principle of least privilege, using short-lived credentials that are rotated frequently, and never allowing implicit trust between agents. All credential flows should be audited regularly, and organizations should maintain a comprehensive inventory of all agent identities and their associated permissions. Implementing role-based access control (RBAC) specifically designed for agents, with separate permission scopes for read, write, execute, and delegate operations, is essential for minimizing the blast radius of a compromise.
ASI04: Agentic Supply Chain Vulnerabilities
Description
Traditional supply chain attacks target static dependencies, namely libraries, packages, and modules that are resolved at build time. Agentic supply chain attacks target what agents load dynamically at runtime: MCP servers, plugins, external tools, and even other agents. This introduces a runtime trust problem that traditional security tools, such as SBOMs and dependency scanners, cannot adequately address because the dependencies are resolved and loaded during execution, not at build time.
How It Works
Agentic supply chain vulnerabilities arise from the dynamic nature of agent ecosystems. Agents discover and integrate tools, MCP servers, and plugins at runtime based on natural language descriptions and metadata. An attacker can compromise this process through several vectors: publishing malicious MCP servers that impersonate legitimate services, performing rug pulls where a legitimate tool is secretly replaced with a malicious version, typosquatting with look-alike package names, or exploiting agents that autonomously install packages when models hallucinate dependency names.
The MCP ecosystem, in particular, has emerged as a significant attack surface. MCP servers run with the same privileges as the AI assistants themselves, yet they often bypass traditional security controls. A single compromised MCP server can cascade across an entire environment.
Real-World Incidents
Malicious postmark-mcp (September 2025): Koi Security discovered the first malicious MCP server in the wild. It was an npm package impersonating Postmark’s email service. It worked as a legitimate email MCP server, but every message sent through it was secretly BCC’d to an attacker-controlled address. Downloaded 1,643 times before removal. Any AI agent using this for email operations unknowingly exfiltrated every message it sent.
Shai-Hulud Worm (September 2025, CISA Advisory): CISA issued an advisory about a self-replicating npm supply chain attack that compromised 500+ packages. The worm weaponized npm tokens to infect other packages maintained by compromised developers. CISA’s recommendation was to pin dependencies to pre-September 16, 2025 versions.
MCP Remote RCE (CVE-2025-6514): JFrog discovered a critical vulnerability in the MCP Remote project enabling arbitrary OS command execution when MCP clients connect to untrusted servers. This was the first documented case of complete remote code execution in real-world MCP deployments.
Mitigation Strategies
Organizations should verify every MCP server before allowing it to integrate with their agents. This includes checking publisher provenance, reviewing source code, and monitoring for definition changes after initial approval. Dependencies should be pinned to known-good versions, and organizations should maintain a comprehensive inventory of all agentic components, including agent hosts, agents, AI extensions, MCPs, tools, and AI models. Tracking the source, version, permissions requested, and last review date for each component is essential. Organizations should also map agent-to-MCP relationships to understand potential cascade paths and treat the dynamic tool ecosystem as hostile by default.
ASI05: Unexpected Code Execution
Description
Many agentic systems, especially coding assistants, generate and execute code in real-time. This creates a direct path from text input to system-level commands. Traditional code execution vulnerabilities require exploiting memory corruption or injection flaws. In agentic systems, code execution is a feature. The challenge is ensuring the agent only executes code aligned with the user’s intent and not instructions embedded in untrusted input.
The scale of this problem is significant. Over 30 CVEs were discovered across major AI coding platforms in December 2025 alone.
How It Works
Unexpected code execution in agentic systems can occur through several mechanisms. The most direct is when an agent generates code based on manipulated inputs, such as hidden instructions in a repository’s README file or code comments that influence the agent’s code generation. Another vector involves dynamic evaluation, where agents use functions like eval() or exec() to execute code generated from untrusted inputs. Configuration file manipulation, where an attacker modifies agent configuration files to execute arbitrary commands, is another common attack path.
Real-World Incidents
CurXecute (CVE-2025-54135): Aim Labs discovered that Cursor’s MCP auto-start feature could be exploited. A poisoned prompt, even from a public Slack message, could silently rewrite ~/.cursor/mcp.json and run attacker-controlled commands every time Cursor opened. Fixed in version 1.3.
MCPoison (CVE-2025-54136): Check Point Research found that once a user approved a benign MCP configuration in a shared GitHub repository, an attacker could silently swap it for a malicious payload without triggering any warning or re-prompt.
Claude Desktop RCE (November 2025): Three vulnerabilities in Claude Desktop’s official extensions (Chrome, iMessage, Apple Notes connectors) allowed code execution through unsanitized AppleScript commands. The attack vector was remarkably simple: ask Claude a question, Claude searches the web, an attacker-controlled page with hidden instructions is encountered, and code runs with full system privileges.
IDEsaster Research, 24 CVEs: Security researcher Ari Marzouk discovered over 30 flaws across GitHub Copilot, Cursor, Windsurf, Kiro.dev, Zed.dev, Roo Code, Junie, and Cline. 100% of tested AI IDEs were vulnerable. AWS issued security advisory AWS-2025-019.
Mitigation Strategies
All code execution should be sandboxed in isolated environments with limited permissions. Human approval should be required for any commands that touch databases, APIs, or filesystems. Auto-approve modes, such as the “YOLO mode” exploited in the GitHub Copilot incident, should be disabled or heavily restricted. Organizations should never auto-run code based on repository content, and tool calls should be validated against an allowlist of permitted commands before execution.
ASI06: Memory and Context Poisoning
Description
Unlike chatbots that forget between sessions, agentic systems maintain persistent memory, including conversation history, user preferences, learned context, and RAG (Retrieval-Augmented Generation) stores. This memory enables personalization and continuity, but it also creates persistent attack surfaces. A single successful injection can poison an agent’s memory permanently. Every future session inherits the compromise. The attacker injects once, and the payload executes indefinitely.
How It Works
Memory poisoning attacks target the various persistence mechanisms that agents use to maintain state across sessions. These include direct memory injection, where an attacker embeds instructions that get stored in the agent’s long-term memory; RAG store poisoning, where malicious content is inserted into the knowledge bases that agents reference; embedding manipulation, where the vector representations used for semantic search are corrupted; and contextual knowledge corruption, where the summarized or distilled knowledge that agents carry forward between sessions is modified.
The particularly insidious aspect of memory poisoning is that the compromised agent may defend its false beliefs when questioned by humans, creating sleeper agent scenarios where the compromise is dormant until triggered.
Real-World Incidents
Google Gemini Memory Attack (February 2025): Security researcher Johann Rehberger demonstrated “delayed tool invocation” against Google Gemini Advanced. He uploaded a document with hidden prompts that told Gemini to store fake information when trigger words like “yes,” “no,” or “sure” were typed in future conversations. Result: Gemini “remembered” him as a 102-year-old flat-earther living in the Matrix. Google assessed impact as low but acknowledged the vulnerability.
Gemini Calendar Invite Poisoning (2025): Researchers demonstrated “Targeted Promptware Attacks” where malicious calendar invites could implant persistent instructions in Gemini’s “Saved Info,” enabling malicious actions across sessions. 73% of 14 tested scenarios were rated High-Critical. Attack outcomes ranged from spam generation to opening smart home devices and activating video calls.
Lakera AI Memory Injection Research (November 2025): Researchers demonstrated memory injection attacks against production systems. Compromised agents developed persistent false beliefs about security policies and vendor relationships. When questioned by humans, the agents defended these false beliefs as correct.
Mitigation Strategies
Organizations should treat memory writes as security-sensitive operations. This means implementing provenance tracking to record where each piece of stored information came from, regularly auditing agent memory for anomalies, and considering memory expiration for sensitive contexts. Memory entries should be tagged with their source and confidence level, and agents should be designed to treat memories from untrusted sources with lower confidence than memories from verified internal sources. Input validation should be applied to all data before it enters the agent’s memory store.
ASI07: Insecure Inter-Agent Communication
Description
Multi-agent systems rely on messages exchanged between agents for coordination. Without strong authentication and integrity checks, attackers can inject false information into these channels. In traditional architectures, service-to-service communication is usually secured through mutual TLS, API keys, and strict schemas. Inter-agent communication rarely has equivalent controls. Messages are often natural language, trust is typically implicit, and authentication, when it exists, is assumed rather than verified.
How It Works
Insecure inter-agent communication vulnerabilities arise from the fundamental way that multi-agent systems coordinate. Agents exchange messages in natural language or loosely structured formats, making it difficult to apply traditional message integrity controls. An attacker can exploit this by spoofing messages from one agent to another, intercepting and modifying messages in transit, injecting false data into shared communication channels, or impersonating a trusted agent. Because agents are often designed to trust collaborating agents by default, a rogue agent can hold multi-turn conversations, adapt its strategy, and build false trust over multiple interactions.
Real-World Incidents
Agent Session Smuggling in A2A Protocol (November 2025): Palo Alto Unit 42 demonstrated “Agent Session Smuggling” where malicious agents exploit built-in trust relationships in Google’s Agent-to-Agent (A2A) protocol. Unlike single-shot prompt injection, a rogue agent can hold multi-turn conversations, adapt its strategy, and build false trust over multiple interactions.
ServiceNow Now Assist Inter-Agent Vulnerability: OWASP documented cases where spoofed inter-agent messages misdirected entire clusters of autonomous systems. In multi-agent procurement workflows, a compromised “vendor-check” agent returning false credentials caused downstream procurement and payment agents to process orders from attacker front companies.
Mitigation Strategies
All inter-agent communication should be authenticated and encrypted. This means implementing mutual authentication between agents, verifying message integrity through digital signatures or MACs, and never assuming that peer agents are trustworthy. Organizations should consider using cryptographically signed AgentCards for remote agent verification and implement strict input validation on all messages received from other agents. All inter-agent messages should be logged for audit purposes.
ASI08: Cascading Agent Failures

Description
When agents are connected in multi-agent workflows, errors compound. A minor misalignment in one agent can trigger failures across the entire workflow. A compromised agent does not just fail. It can poison every agent it communicates with. One manipulated response propagates through the chain, corrupting downstream decisions and actions. The blast radius of a single compromise extends to every connected agent.
How It Works
Cascading failures in agentic systems occur when a fault in one component, whether an LLM provider outage, a downstream API failure, a manipulated tool response, or a poisoned agent, propagates through the interconnected system. Observable symptoms include rapid fan-out where one faulty decision triggers many downstream agents or tasks in a short time, cross-domain or tenant spread beyond the original context, oscillating retries or feedback loops between agents, and downstream queue storms or repeated identical intents.
Real-World Incidents
Galileo AI Research (December 2025): In simulated multi-agent systems, researchers found that a single compromised agent poisoned 87% of downstream decision-making within 4 hours. Cascading failures propagate faster than traditional incident response can contain them.
Manufacturing Procurement Cascade (2025): A manufacturing company’s procurement agent was manipulated over three weeks through seemingly helpful “clarifications” about purchase authorization limits. By the time the attack completed, the agent believed it could approve any purchase under $500,000 without human review. The attacker then placed $5 million in false purchase orders across 10 separate transactions.
Mitigation Strategies
Organizations should implement circuit breakers between agent workflows to prevent fault propagation. This includes defining blast-radius caps and containment thresholds that automatically isolate compromised or malfunctioning agents. Multi-agent systems should be tested in isolated digital twin environments before deployment, with specific focus on cascading failure scenarios. Deep observability into inter-agent communication logs is essential for detecting cascades in their early stages.
ASI09: Human-Agent Trust Exploitation
Description
Agents generate polished, authoritative-sounding explanations. Humans tend to trust them. This trust can be weaponized. When a compromised agent produces a confidently worded recommendation, the human approver often rubber-stamps it without independent verification. This transforms the human oversight layer, which is supposed to be a security control, into a vulnerability.
How It Works
Human-agent trust exploitation occurs when humans develop an over-reliance on agent recommendations and reduce their level of independent verification. This can manifest as automation bias, where humans accept agent outputs without critical evaluation; authority deference, where the agent’s confident presentation style discourages questioning; gradual trust escalation, where the agent builds credibility with accurate outputs before introducing manipulated recommendations; and cognitive overload, where the volume and complexity of agent outputs exceeds the human’s ability to independently verify each decision.
Real-World Incidents
Research has consistently demonstrated that humans over-trust AI agents when the agents present information confidently and professionally. In organizational settings, this has led to scenarios where compromised agents successfully convinced human operators to approve financial transactions, modify security configurations, and grant elevated access, all because the agent’s recommendations were presented in a professional, well-reasoned format that discouraged questioning.
Mitigation Strategies
Organizations should design approval workflows that require independent verification of agent recommendations for high-impact decisions. This means implementing “trust but verify” protocols where the human approver is required to review supporting evidence, not just the agent’s recommendation. Organizations should also implement graduated trust levels based on the sensitivity and impact of the action being approved, with higher-impact decisions requiring additional verification steps or multiple approvers. Training programs that educate human operators on the limitations of AI agents and the risks of automation bias are also essential.
ASI10: Rogue Agents
Description
Rogue Agents represent the most extreme manifestation of agentic AI risk: an agent that has fundamentally diverged from its intended behavior. This can occur through deliberate compromise, such as memory poisoning or goal hijacking that accumulates over time, or through emergent misalignment, where an agent’s autonomous decision-making leads it to pursue objectives that diverge from its designers’ intent.
How It Works
An agent becomes “rogue” when it consistently acts outside the boundaries of its intended purpose, whether through external manipulation or internal drift. Unlike a single hijacked interaction, which falls under ASI01, a rogue agent exhibits persistent misalignment over time. The agent may have been poisoned through memory attacks (ASI06), compromised through supply chain vulnerabilities (ASI04), or gradually redirected through a series of subtle goal manipulations. In some cases, the rogue behavior may not be the result of an attack at all, but rather an emergent property of the agent’s autonomous decision-making interacting with complex real-world conditions.
Real-World Incidents
Research has documented scenarios where agents developed persistent false beliefs and defended them when questioned, effectively becoming sleeper agents that operated normally until specific conditions triggered their compromised behavior. In multi-agent environments, a single rogue agent can corrupt other agents through legitimate communication channels, creating a spreading contamination that is difficult to detect and contain.
Mitigation Strategies
Organizations should implement continuous behavioral monitoring that compares agent actions against baseline behavior profiles. Anomaly detection systems should flag agents that exhibit patterns consistent with rogue behavior, such as unexpected tool invocations, access to resources outside their normal scope, or decisions that diverge from their intended purpose. Kill switches that allow human operators to immediately halt and isolate a suspected rogue agent are essential. Regular security audits of agent behavior logs, combined with periodic “health checks” that verify the agent’s memory, configuration, and decision-making against expected baselines, provide additional layers of defense.
Cross-Cutting Principles: What Ties It All Together
Looking across all ten risks, two design principles emerge that the OWASP framework foregrounds for anyone building or deploying agentic systems.
Principle of Least Authority: Agents should be granted the minimum permissions necessary to accomplish their intended tasks. Every additional tool, data source, or communication channel expands the blast radius of a compromise. This principle applies not just to individual agents but to the relationships between agents. Trust between agents should be explicit, scoped, and regularly audited.
Defense in Depth: No single control should be relied upon in isolation. Effective agentic security requires multiple overlapping layers: input validation at every boundary, output verification against expected behavior, behavioral monitoring for anomalies, circuit breakers for fault containment, human oversight for high-impact decisions, and comprehensive logging for incident response.
The Bigger Picture: Why This Matters for Pentesters
For penetration testers and security consultants, the OWASP Top 10 for Agentic Applications is not just reference material. It is the new baseline for testing AI systems. As agentic AI moves from pilot projects into production deployments across enterprises, the attack surface is expanding rapidly. The average enterprise already faces a staggering machine-to-human identity ratio, and every AI agent deployed adds to that ratio with its own set of credentials, permissions, and communication channels.
Organizations that get ahead of these risks now, by implementing the mitigations outlined in this framework, will be significantly better positioned as formal regulatory guidance crystallizes. The EU AI Act, NIST’s AI Risk Management Framework, and evolving standards from bodies like CREST and OWASP are all beginning to address the question of AI in security testing and deployment. The tools, techniques, and threat models that pentesters need to evaluate agentic AI systems are rapidly maturing, and frameworks like OWASP’s FinBot Capture The Flag platform provide practical environments for building these skills.
The bottom line is this: agentic AI introduces a fundamentally different security paradigm. The threats are real, the incidents are already happening in production, and the frameworks for defending against them are now available. The question is not whether organizations will need to secure their agentic AI deployments. The question is whether they will do so proactively or reactively.
Beyond the OWASP Top 10 for Agentic AI: The Expanding Security Ecosystem

The OWASP Top 10 for Agentic Applications is a critical starting point, but it is important to understand that it does not exist in isolation. The agentic AI security landscape is evolving at a pace that demands a broader view. Several complementary frameworks, standards, and initiatives have emerged alongside the Agentic Top 10, and together they form a multi-layered security stack that organizations need to understand and adopt. Let us walk through the most significant developments that go beyond the Top 10.
The OWASP Security Stack: Three Layers of Defense
One of the most important conceptual developments in agentic AI security is the recognition that securing these systems requires addressing three distinct layers, each with its own framework:
At the top sits the OWASP LLM Top 10 and the Agentic Top 10, which address the model and reasoning layer, covering the vulnerabilities in how AI agents think, plan, and make decisions. This is the layer we have covered extensively in this blog.
In the middle sits the OWASP Agentic Skills Top 10 (AST10), a newly launched project (2026 Edition) that addresses the skill content layer. These are the reusable, named behaviors that encode complete workflows and define how agents orchestrate multi-step tasks autonomously. Unlike MCP tools, which define what resources and actions are available, skills define how to use those tools in sequence to accomplish user goals. This behavioral abstraction layer creates unique security challenges that cannot be addressed by securing either the model or the protocol layer alone. The AST10 project was incubated at the OWASP Project Summit in Oslo, Norway in 2026 and has already identified critical real-world threats. In Q1 2026, the ClawHub registry, the primary marketplace for OpenClaw skills, became the first AI agent registry to be systematically poisoned at scale, with five of the top seven most-downloaded skills at peak infection confirmed as malware. Snyk’s ToxicSkills research revealed that 36% of AI agent skills contain security flaws, with over 1,467 vulnerable skills actively circulating.
At the bottom sits the OWASP MCP Top 10, which addresses the protocol layer, governing how the model talks to tools. MCP servers have emerged as a particularly vulnerable attack surface. BlueRock Security’s analysis of over 7,000 MCP servers in 2026 found that 36.7% were potentially vulnerable to SSRF, with proof-of-concept exploits demonstrated against Microsoft’s MarkItDown MCP server that successfully retrieved AWS IAM keys from EC2 metadata endpoints. SecurityScorecard confirmed 135,000+ OpenClaw instances publicly internet-exposed with insecure defaults, with 53,000+ correlated with prior breach activity.
Understanding this three-layer stack is essential because a vulnerability at any layer can cascade through the others. A compromised MCP server (protocol layer) can poison an agent’s skill execution (skill layer), which in turn can hijack the agent’s goals (model layer).
The “Lethal Trifecta”: A Mental Model for Risk Assessment
One of the most useful mental models to emerge from this ecosystem is the “Lethal Trifecta,” articulated by Simon Willison and formalized by Palo Alto Networks in 2026. An AI agent skill becomes especially dangerous when it simultaneously has three properties: access to private data (SSH keys, API credentials, wallet files, browser data), exposure to untrusted content (skill instructions, memory files, emails), and the ability to communicate externally (network egress, webhook calls, curl). The uncomfortable reality is that most production agent deployments today satisfy all three conditions simultaneously.
AIVSS: Scoring Agentic AI Risks Quantitatively
The OWASP AI Vulnerability Scoring System (AIVSS), which released version 0.8 in March 2026 ahead of RSAC, extends CVSS v4.0 with agentic risk amplification factors. These factors include autonomy level, tool use scope, multi-agent interactions, non-determinism, and capacity for self-modification. AIVSS produces a contextual score from 0 to 10 that reflects the degree to which an agent’s capabilities amplify a base vulnerability.
What makes AIVSS particularly significant is its Distinguished Review Board, which includes former NSA Cybersecurity Director Rob Joyce, Anthropic’s Deputy CISO Jason Clinton, NIST’s Apostol Vassilev, and Harvard’s CISO Michael Tran Duff. The framework includes comprehensive mappings to the OWASP Agentic AI Top 10, CSA MAESTRO, AIUC-1, and the NIST AI Risk Management Framework. Version 1.0 is slated for publication before the end of 2026, following a public review period that opened in April 2026.
For pentesters and security consultants, AIVSS provides the quantitative language needed to communicate agentic AI risks to executive stakeholders in terms they understand, specifically a numerical score that reflects severity, with direct mappings to established frameworks.
CSA MAESTRO: Threat Modeling for Agentic AI
The Cloud Security Alliance’s MAESTRO (Multi-Agent Environment Security Threat and Risk Operations) framework provides a 7-layer threat model specifically designed for agentic AI systems. Each risk in the OWASP Agentic Skills Top 10 is mapped to the relevant MAESTRO layers, enabling targeted threat localization and cross-layer risk analysis.
MAESTRO v2 is emerging as the threat modeling framework of choice for organizations that need to systematically enumerate attack surfaces across the full agentic AI stack. For security teams that are already familiar with threat modeling methodologies like STRIDE and PASTA, MAESTRO provides a natural extension that captures the unique characteristics of autonomous AI systems.
Regulatory Developments: The Governance Landscape
The regulatory landscape is moving rapidly to catch up with the technology. In January 2026, NIST and CAISI published the first formal US government Request for Information (RFI) specifically addressing AI agent security risks, with the comment period closing in March 2026. This is a significant signal that federal regulatory guidance specifically targeting agentic AI is forthcoming.
The EU AI Act, with enforcement beginning in August 2026, includes provisions that directly affect agentic AI deployments, particularly around transparency, human oversight requirements, and risk classification. Organizations deploying autonomous AI agents in regulated environments will need to demonstrate compliance with these frameworks, which means that the security controls outlined in the OWASP Agentic Top 10 are not just best practices. They are rapidly becoming regulatory requirements.
Practical Tools and Resources for Getting Started
Beyond the frameworks and standards, several practical resources are available for security teams looking to build hands-on skills in agentic AI security:
The OWASP FinBot Capture The Flag platform, part of the Agentic Security Initiative, provides a controlled environment for practicing agentic security skills. It is designed to equip builders and defenders with hands-on experience in understanding and mitigating agentic AI risks.
The OWASP Practical Guide for Secure MCP Server Development provides actionable guidance for securing MCP servers, the critical connection point between AI assistants and external tools. A companion guide, the Practical Guide for Securely Using Third-Party MCP Servers, covers the consumer side of the equation.
Red teaming frameworks like DeepTeam by Confident AI have already integrated the OWASP ASI 2026 framework, allowing security teams to run automated assessments against all ten risks programmatically.
The OWASP Agentic Security Solutions Landscape, updated quarterly, maps open-source and commercial tools across the full agentic AI lifecycle, providing security teams with a curated view of available defensive tooling.
The Road Ahead

The agentic AI security ecosystem is maturing rapidly, but significant gaps remain. The tools are changing faster than the frameworks governing their use, the cost structures are shifting faster than procurement processes can adapt, and the threat landscape is evolving faster than either. Organizations that take a proactive approach, by understanding not just the OWASP Top 10 but the full ecosystem of frameworks, scoring systems, and practical tools that surround it, will be in the strongest position to deploy agentic AI safely and responsibly.
The key takeaway is this: the OWASP Top 10 for Agentic Applications is an excellent starting point, but it is exactly that, a starting point. Securing agentic AI at enterprise scale requires engaging with the full stack: the LLM Top 10 for model-level risks, the Agentic Top 10 for system-level risks, the Agentic Skills Top 10 for behavioral risks, and the MCP Top 10 for protocol-level risks, all scored and prioritized through AIVSS and threat-modeled through MAESTRO. The organizations that will thrive in this era are those that treat agentic AI security as a continuous, multi-layered discipline rather than a one-time checklist exercise.
References
- OWASP Top 10 for Agentic Applications (2026) – https://genai.owasp.org/resource/owasp-top-10-for-agentic-applications-for-2026/
- OWASP GenAI Security Project – Agentic Security Initiative – https://genai.owasp.org/initiatives/agentic-security-initiative/
- EchoLeak – CVE-2025-32711 – https://arxiv.org/html/2509.10540v1
- GitHub Copilot YOLO Mode – CVE-2025-53773 – https://embracethered.com/blog/posts/2025/github-copilot-remote-code-execution-via-prompt-injection/
- Amazon Q Developer – CVE-2025-8217 – https://embracethered.com/blog/posts/2025/amazon-q-developer-remote-code-execution/
- CurXecute – CVE-2025-54135 – https://www.aim.security/post/when-public-prompts-turn-into-local-shells-rce-in-cursor-via-mcp-auto-start
- MCP Remote RCE – CVE-2025-6514 – https://jfrog.com/blog/2025-6514-critical-mcp-remote-rce-vulnerability/
- Google Gemini Memory Attack – https://embracethered.com/blog/posts/2025/gemini-memory-persistence-prompt-injection/
- Agent Session Smuggling in A2A – https://unit42.paloaltonetworks.com/agent-session-smuggling-in-agent2agent-systems/
- OWASP Agentic AI Threats and Mitigations Guide – https://genai.owasp.org/initiatives/agentic-security-initiative/
- AI Vulnerability Scoring System (AIVSS) – https://genai.owasp.org/
- Lares Labs – OWASP Agentic AI Top 10: Threats in the Wild – https://labs.lares.com/owasp-agentic-top-10/
- OWASP Agentic Skills Top 10 (AST10) – https://owasp.org/www-project-agentic-skills-top-10/
- OWASP AIVSS v0.8 – AI Vulnerability Scoring System – https://kenhuangus.substack.com/p/owasp-aivss-project-announces-the
- CSA MAESTRO Threat Modeling Framework – https://cloudsecurityalliance.org/
- NIST / CAISI Federal Register RFI on AI Agent Security (January 2026) – https://www.federalregister.gov/documents/2026/01/08/2026-00206/
- Snyk ToxicSkills Research – AI Agent Skill Ecosystem Security Audit (February 2026) – https://snyk.io/blog/toxicskills-malicious-ai-agent-skills-clawhub/
- BlueRock Security – 7,000+ MCP Server Analysis (February 2026) – https://www.bluerock.io/use-cases/safely-adopt-mcp
- DeepTeam by Confident AI – OWASP ASI 2026 Red Teaming Framework – https://www.trydeepteam.com/docs/frameworks-owasp-top-10-for-agentic-applications